 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForeSci: Evaluating LLM Agents for Forward-Looking AI Research Judgment
May 30, 2026AI research often requires decisions before future evidence exists: which bottleneck to attack, which direction to pursue, or where a project should be positioned. We introduce ForeSci, a temporally controlled benchmark for evaluating whether LLM agents can make such forward-looking research judgements from historical evidence. ForeSci contains 500 tasks across four fast-moving AI domains and four decision families. Each task is paired with a cutoff-aligned offline knowledge base; post-cutoff papers are hidden during generation and used only for validation. To avoid random future-event prediction, tasks are derived from pre-cutoff taxonomy branches and evidence signals, and answer-generation backbones are selected to precede the task cutoffs. We evaluate native LLMs, Hybrid RAG, and three research-agent adaptations across four backbones. Results show that explicit evidence organization improves traceability and factual support, but gains depend strongly on the decision family. Diagnostics reveal a recurring evidence-decision decoupling: agents may cite relevant evidence while forecasting the wrong research object. ForeSci turns forward-looking AI research judgement into a controlled benchmark for evaluating research agents as decision-making systems.
SciCustom: A Framework for Custom Evaluation of Scientific Capabilities in Large Language Models
May 19, 2026Large language models (LLMs) are increasingly applied to scientific research, yet existing evaluations often fail to reflect the fine-grained capabilities required in practice. Most benchmarks are manually curated or domain-generic, limiting scalability and alignment with real scientific use cases. In this paper, we propose a new framework named SciCustom to address the problem. It enables the custom construction of benchmarks from large-scale scientific data to evaluate application-specific scientific capabilities in LLMs. SciCustom first organizes scientific knowledge into ontology-grounded knowledge units with controlled granularity and trains a tagger to map large-scale data instances into this knowledge space. Given a custom requirement, relevant knowledge units are identified via voting-based multi-model consensus. These units enable relevance-aware benchmark retrieval via binary search, followed by proxy subset selection and data-grounded benchmark generation for efficient evaluation. Experiments in chemistry and healthcare demonstrate that SciCustom reveals fine-grained differences in LLM scientific capabilities that standard benchmarks overlook, while requiring neither expert annotation nor synthetic question generation. This work provides a scalable and application-aware foundation for benchmarking scientific capabilities in LLMs. The source code is available at https://github.com/yjwtheonly/SciCustom.
CoPA: Benchmarking Personalized Question Answering with Data-Informed Cognitive Factors
Apr 16, 2026While LLMs have demonstrated remarkable potential in Question Answering (QA), evaluating personalization remains a critical bottleneck. Existing paradigms predominantly rely on lexical-level similarity or manual heuristics, often lacking sufficient data-driven validation. We address this by mining Community-Individual Preference Divergence (CIPD), where individual choices override consensus, to distill six key personalization factors as evaluative dimensions. Accordingly, we introduce CoPA, a benchmark with 1,985 user profiles for fine-grained, factor-level assessment. By quantifying the alignment between model outputs and user-specific cognitive preferences inferred from interaction patterns, CoPA provides a more comprehensive and discriminative standard for evaluating personalized QA than generic metrics. The code is available at https://github.com/bjzgcai/CoPA.
STAGE: A Benchmark for Knowledge Graph Construction, Question Answering, and In-Script Role-Playing over Movie Screenplays
Jan 13, 2026Movie screenplays are rich long-form narratives that interleave complex character relationships, temporally ordered events, and dialogue-driven interactions. While prior benchmarks target individual subtasks such as question answering or dialogue generation, they rarely evaluate whether models can construct a coherent story world and use it consistently across multiple forms of reasoning and generation. We introduce STAGE (Screenplay Text, Agents, Graphs and Evaluation), a unified benchmark for narrative understanding over full-length movie screenplays. STAGE defines four tasks: knowledge graph construction, scene-level event summarization, long-context screenplay question answering, and in-script character role-playing, all grounded in a shared narrative world representation. The benchmark provides cleaned scripts, curated knowledge graphs, and event- and character-centric annotations for 150 films across English and Chinese, enabling holistic evaluation of models' abilities to build world representations, abstract and verify narrative events, reason over long narratives, and generate character-consistent responses.
NatureLM: Deciphering the Language of Nature for Scientific Discovery
Feb 11, 2025



Foundation models have revolutionized natural language processing and artificial intelligence, significantly enhancing how machines comprehend and generate human languages. Inspired by the success of these foundation models, researchers have developed foundation models for individual scientific domains, including small molecules, materials, proteins, DNA, and RNA. However, these models are typically trained in isolation, lacking the ability to integrate across different scientific domains. Recognizing that entities within these domains can all be represented as sequences, which together form the "language of nature", we introduce Nature Language Model (briefly, NatureLM), a sequence-based science foundation model designed for scientific discovery. Pre-trained with data from multiple scientific domains, NatureLM offers a unified, versatile model that enables various applications including: (i) generating and optimizing small molecules, proteins, RNA, and materials using text instructions; (ii) cross-domain generation/design, such as protein-to-molecule and protein-to-RNA generation; and (iii) achieving state-of-the-art performance in tasks like SMILES-to-IUPAC translation and retrosynthesis on USPTO-50k. NatureLM offers a promising generalist approach for various scientific tasks, including drug discovery (hit generation/optimization, ADMET optimization, synthesis), novel material design, and the development of therapeutic proteins or nucleotides. We have developed NatureLM models in different sizes (1 billion, 8 billion, and 46.7 billion parameters) and observed a clear improvement in performance as the model size increases.
SMI-Editor: Edit-based SMILES Language Model with Fragment-level Supervision
Dec 07, 2024



SMILES, a crucial textual representation of molecular structures, has garnered significant attention as a foundation for pre-trained language models (LMs). However, most existing pre-trained SMILES LMs focus solely on the single-token level supervision during pre-training, failing to fully leverage the substructural information of molecules. This limitation makes the pre-training task overly simplistic, preventing the models from capturing richer molecular semantic information. Moreover, during pre-training, these SMILES LMs only process corrupted SMILES inputs, never encountering any valid SMILES, which leads to a train-inference mismatch. To address these challenges, we propose SMI-Editor, a novel edit-based pre-trained SMILES LM. SMI-Editor disrupts substructures within a molecule at random and feeds the resulting SMILES back into the model, which then attempts to restore the original SMILES through an editing process. This approach not only introduces fragment-level training signals, but also enables the use of valid SMILES as inputs, allowing the model to learn how to reconstruct complete molecules from these incomplete structures. As a result, the model demonstrates improved scalability and an enhanced ability to capture fragment-level molecular information. Experimental results show that SMI-Editor achieves state-of-the-art performance across multiple downstream molecular tasks, and even outperforming several 3D molecular representation models.
MolXPT: Wrapping Molecules with Text for Generative Pre-training
May 26, 2023



Generative pre-trained Transformer (GPT) has demonstrates its great success in natural language processing and related techniques have been adapted into molecular modeling. Considering that text is the most important record for scientific discovery, in this paper, we propose MolXPT, a unified language model of text and molecules pre-trained on SMILES (a sequence representation of molecules) wrapped by text. Briefly, we detect the molecule names in each sequence and replace them to the corresponding SMILES. In this way, the SMILES could leverage the information from surrounding text, and vice versa. The above wrapped sequences, text sequences from PubMed and SMILES sequences from PubChem are all fed into a language model for pre-training. Experimental results demonstrate that MolXPT outperforms strong baselines of molecular property prediction on MoleculeNet, performs comparably to the best model in text-molecule translation while using less than half of its parameters, and enables zero-shot molecular generation without finetuning.
A Comprehensive Survey on Deep Graph Representation Learning
Apr 19, 2023



Graph representation learning aims to effectively encode high-dimensional sparse graph-structured data into low-dimensional dense vectors, which is a fundamental task that has been widely studied in a range of fields, including machine learning and data mining. Classic graph embedding methods follow the basic idea that the embedding vectors of interconnected nodes in the graph can still maintain a relatively close distance, thereby preserving the structural information between the nodes in the graph. However, this is sub-optimal due to: (i) traditional methods have limited model capacity which limits the learning performance; (ii) existing techniques typically rely on unsupervised learning strategies and fail to couple with the latest learning paradigms; (iii) representation learning and downstream tasks are dependent on each other which should be jointly enhanced. With the remarkable success of deep learning, deep graph representation learning has shown great potential and advantages over shallow (traditional) methods, there exist a large number of deep graph representation learning techniques have been proposed in the past decade, especially graph neural networks. In this survey, we conduct a comprehensive survey on current deep graph representation learning algorithms by proposing a new taxonomy of existing state-of-the-art literature. Specifically, we systematically summarize the essential components of graph representation learning and categorize existing approaches by the ways of graph neural network architectures and the most recent advanced learning paradigms. Moreover, this survey also provides the practical and promising applications of deep graph representation learning. Last but not least, we state new perspectives and suggest challenging directions which deserve further investigations in the future.
Robust Dancer: Long-term 3D Dance Synthesis Using Unpaired Data
Mar 29, 2023



How to automatically synthesize natural-looking dance movements based on a piece of music is an incrementally popular yet challenging task. Most existing data-driven approaches require hard-to-get paired training data and fail to generate long sequences of motion due to error accumulation of autoregressive structure. We present a novel 3D dance synthesis system that only needs unpaired data for training and could generate realistic long-term motions at the same time. For the unpaired data training, we explore the disentanglement of beat and style, and propose a Transformer-based model free of reliance upon paired data. For the synthesis of long-term motions, we devise a new long-history attention strategy. It first queries the long-history embedding through an attention computation and then explicitly fuses this embedding into the generation pipeline via multimodal adaptation gate (MAG). Objective and subjective evaluations show that our results are comparable to strong baseline methods, despite not requiring paired training data, and are robust when inferring long-term music. To our best knowledge, we are the first to achieve unpaired data training - an ability that enables to alleviate data limitations effectively. Our code is released on https://github.com/BFeng14/RobustDancer
MetaFill: Text Infilling for Meta-Path Generation on Heterogeneous Information Networks
Oct 14, 2022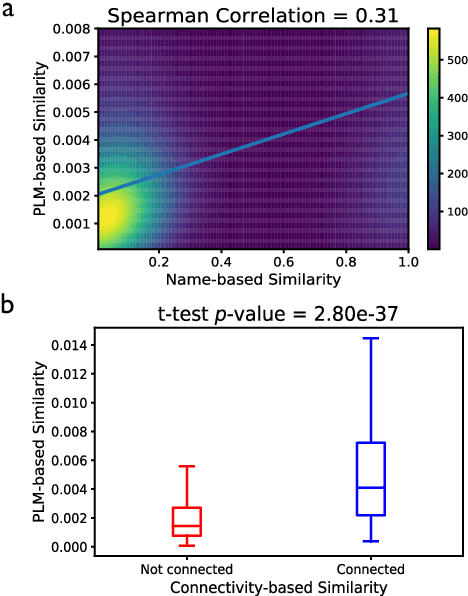
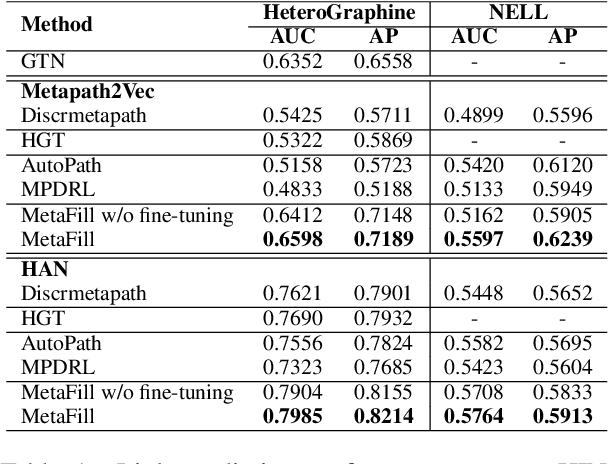
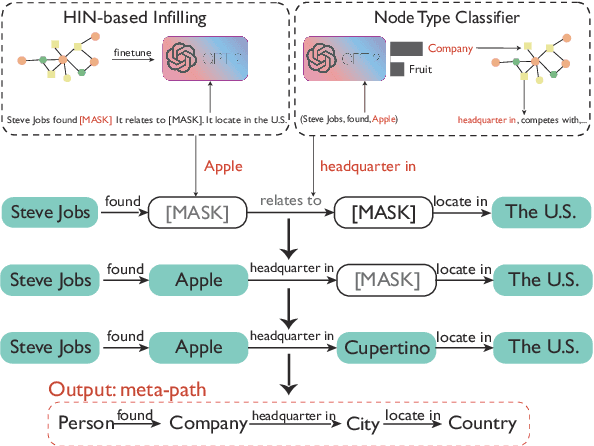

Heterogeneous Information Network (HIN) is essential to study complicated networks containing multiple edge types and node types. Meta-path, a sequence of node types and edge types, is the core technique to embed HINs. Since manually curating meta-paths is time-consuming, there is a pressing need to develop automated meta-path generation approaches. Existing meta-path generation approaches cannot fully exploit the rich textual information in HINs, such as node names and edge type names. To address this problem, we propose MetaFill, a text-infilling-based approach for meta-path generation. The key idea of MetaFill is to formulate meta-path identification problem as a word sequence infilling problem, which can be advanced by Pretrained Language Models (PLMs). We observed the superior performance of MetaFill against existing meta-path generation methods and graph embedding methods that do not leverage meta-paths in both link prediction and node classification on two real-world HIN datasets. We further demonstrated how MetaFill can accurately classify edges in the zero-shot setting, where existing approaches cannot generate any meta-paths. MetaFill exploits PLMs to generate meta-paths for graph embedding, opening up new avenues for language model applications in graph analysis.